01背包问题 问题抽象:有N个物体,每一个重量为c[i],各自的价值为w[i],背包最大容量为V,求背包能放下的物品总和的最大价值 DP思想解决问题 每一个物体都有被放入和不被放入的可能,当前被选择的物体是否被放入所产生的最大价值和后续的物体无关(无后效性),只和前面已经放入的物体的总价值 有关(重叠子问题),前面的最优,加上当前的物体一定最优(最优子结构) 转移方程 f[i][v]表示将第i种物体放入容量为v的背包能达到的最大价值 f[i][v]=max{f[i-1][v], f[i-1][v-c[i]]+w[i…
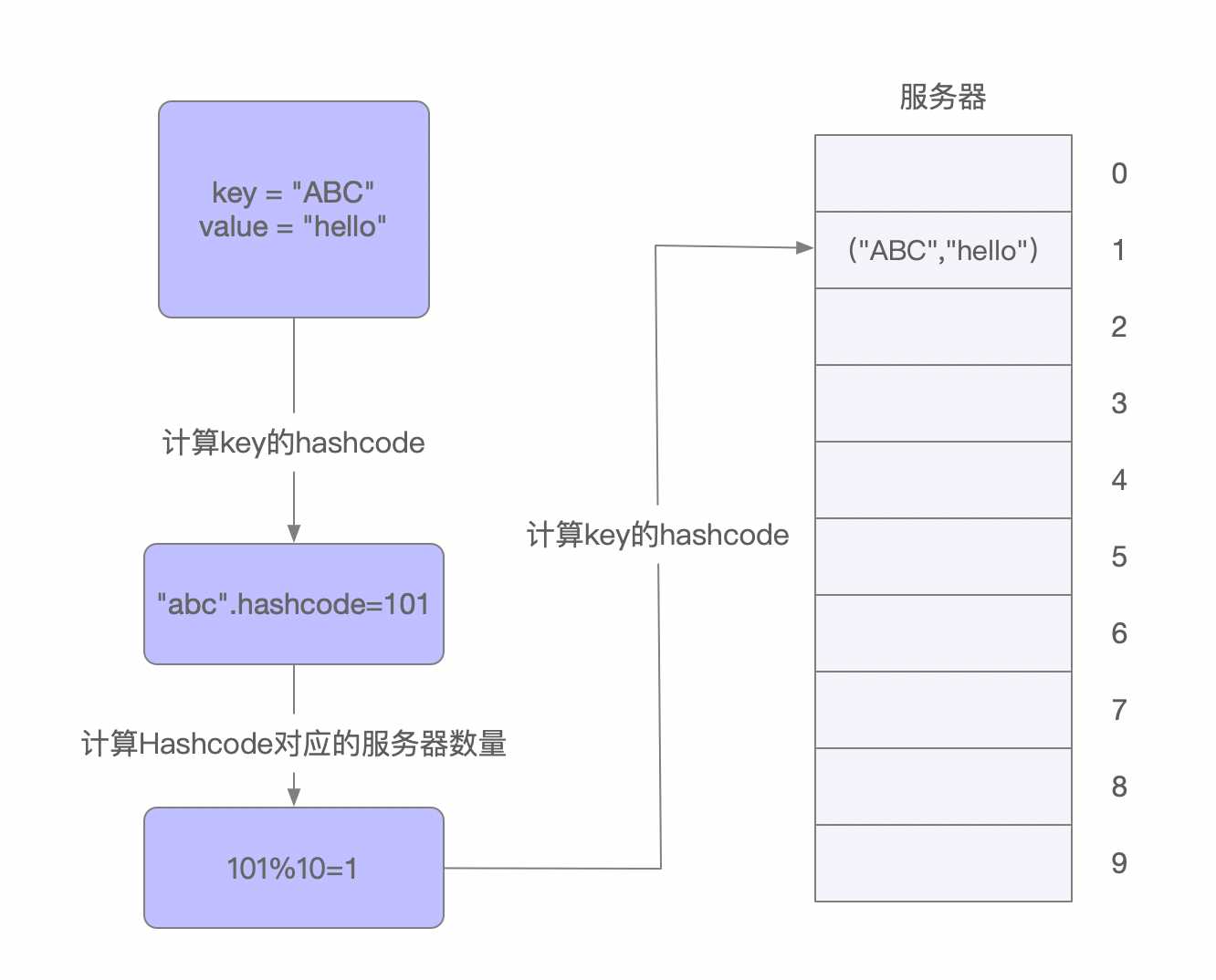
普通Hash算法 我们在实现服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin)、哈希算法(HASH)、最少连接算法(Least Connection)、响应速度算法(Response Time)、加权法(Weighted )等。其中哈希算法是最为常用的算法. 典型的应用场景是: 有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均分发到每台服务器上,每台机器负责1/N的服务。 分配的的原则就是,通过计算请求的hash值来决定请求由哪一台服务器来服务serverID…

最近参加了鹅厂的实习面试,总结一下问题和答案如下: 最近的鹅厂的一面经历如下: - 1)自我介绍 这个环节是每个公司每一轮面试都会有的,一般是三五分钟,突出自己的重点和亮点就行。 - 1.1)问了问是什么类型的硕士,以及什么时间可以去实习 - 1.2)问了在本科和研究生阶段做过的认为最大项目(这一关如果卡住的话非常的尴尬) 2)问了熟悉的语言,然后开始做题: 2.1) 第一题: 输入一个日志文件(sysbench log)、每一秒动态更新,编写函数,当有连续3条日志tps值小于整个tps均值80%打印err信息 […

并查集适用来高效地处理不相交集合(disjoint sets)的合并及查询问题。尤其是出现判断数据的相交情况时,尤其的高效。例如LeetCode的684题:无向图寻找闭环。原题如下: 在本问题中, 树指的是一个连通且无环的无向图。 输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。 附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。 结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v],满足u < v,表示连接顶点u和v的无向…
买卖股票的最佳时机是经典的动态规划问题,即使它有一些取巧的办法(这些“办法”也是DP做法的优化版本)。 简单版本 简单版本:给定一个数组,它的第i 个元素是一支给定股票第 i 天的价格。如果你最多只允许完成一笔交易(即买入和卖出一支股票一次),设计一个算法来计算你所能获取的最大利润。 注意:你不能在买入股票前卖出股票。 示例 1: 输入: [7,1,5,3,6,4] 输出: 5 解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。 注意利润…
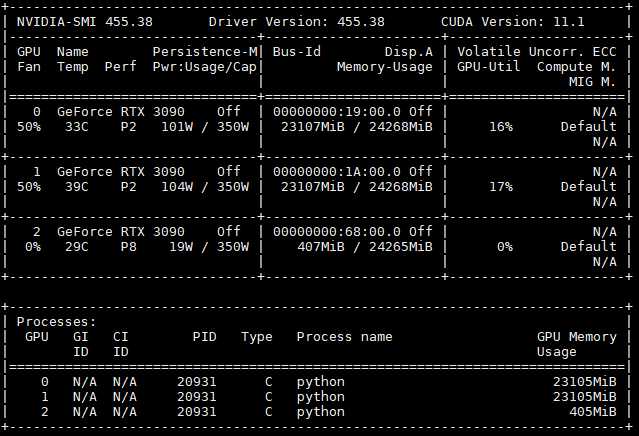
近期实验室新购买一台服务器,配备了全新的3块RTX3090显卡。由于需要安装全新的显卡驱动以及CUDA,cuDNN才能正常使用。 使用watch -n 1 nvidia-smi可以时时实时查看所有显卡的使用情况,并且可以查看驱动版本以及需要的CUDA版本,如下所示:驱动版本是455.38,需要的CUDA为11.1版本(这是我已经安装好了驱动的情况下显示的),如果你的驱动版本过低或者没有安装驱动,那么请参考其他的文章进行安装。 另外,建议使用Anaconda进行环境管理,不容导致整体包环境错乱。 安装Tensorfl…
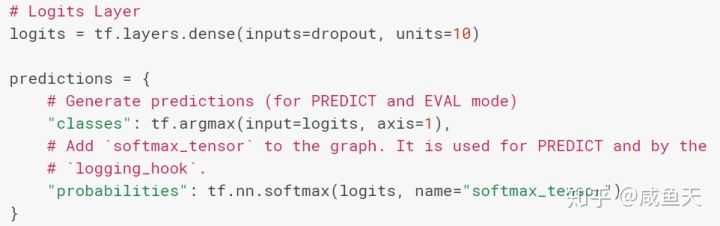
深度学习源码中经常出现的logits其实和统计中定义的logit=log(\frac{p}{1-p})没什么太大关系,就是定义的神经网络的一层输出结果。该输出一般会再接一个softmax layer输出normalize 后的概率,用于多分类。见下图:
最近由于需求,需要重载Keras的Model类,代码逻辑是好好的,但是最后运行的时候出现了NoImplementError这个错误,现实的是self.compute_output_shape没有在子类当中实现。代码如下: from keras import Model class ACModel(Model): ''' Comment model class for actor and critic model ''' def __init__(self,state_size,action_size): super…
Transfer Learning对于没有大量计算资源,并且需要快速构造现有模型的人而言是极大的福音。我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型(对于结构或许有微调)从而加快并优化模型的学习效率不用像大多数网络那样从零开始学习。 而Fine-tuning则属于Transfer Learning下的一个小小的分支。和字面意思一样,就是微调,但是什么才算微调呢?调整输入的结构?调整输出的结构?这并没有确切的概念,但主流观点还是认为调整并重新训练末尾几层的参数属于Fine-…