在搭建自己的Model的时候,我们有时候需要自己从稍微低层的部分进行搭建,而不是直接用Sequential搭建模型,或者是使用Model(inputs,outputs)的方式搭建,例如下面这个简单的例子: # from tensorflow.python import keras # from tensorflow.keras.layers import Dense,Input # 直接使用keras或者是从tensorflow当中导入keras,两种方式二选一 import keras from keras.la…
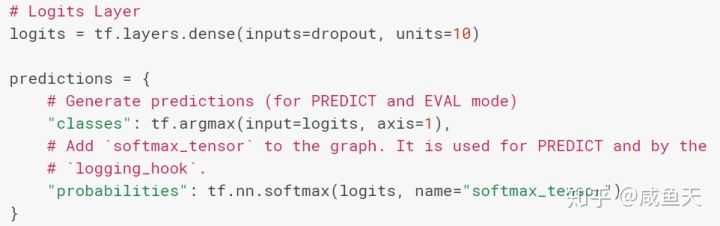
深度学习源码中经常出现的logits其实和统计中定义的logit=log(\frac{p}{1-p})没什么太大关系,就是定义的神经网络的一层输出结果。该输出一般会再接一个softmax layer输出normalize 后的概率,用于多分类。见下图:

Tensorflow的变量(Variable)或优化器(Optimizer)当中有一个use_locking的可选参数,一开始以为是字面意思:直接锁定不给更新参数,后来发现并不是,而是在更新参数的时候使用锁,避免受多线程、多进程、以及在分布式模型中参数更新时受到影响,最典型使用就是在A3C算法当中Global_Actor的优化器当中设置use_locking=true使得更新时不会出现争抢现象。
什么是MDN 对于一输入对一的输出的任务,传统的神经网络可以很好地进行预测/回归/分类。然而,对于一对多的问题,传统的网络无法胜任,此时MDN派上用场。 MDN的工作机制 与传统的NN不一样的是,MDN的预测输出是特定分布的参数值,例如指定三个正态分布进行叠加模拟,需要6个\mu,\sigma参数,那么网络输出为6个参数,输入还是常见的输入,得到正常的6个参数之后,采用f(x)=\sum_{i=0}^{3}\frac{1}{\sqrt{2\pi}\sigma_{i}}e^{\frac{(x-\mu_{i})^2}{…
一点碎碎念 最近这几天,在搞华为的软件精英挑战赛,虽然比赛打的不咋地,但是好在能把以前的数据结构,图论相关知识复习一下(心态还是要摆正的)。不过话说回来,参加华为软件精英挑战赛,一定要熟悉C++,其他的Python,Java,C都是弟弟,不然时间上吃大亏。今年的初赛考察的是有向图寻找闭环的知识点,既然考察了有向图,那就顺带把无向图也一块温习一遍。 图的基本分类与储存 图的分类依据有很多种,比较重要的两种分类依据就是分为有向图和无向图,稀疏图和稠密图。如何正确的分类会直接影响之后算法的选择,其中有向图和无向图…